Images cannot be crawled because of robots.txt restriction: A Google Merchant Center Fallacy
Published: March 7, 2018
Recently at Something Digital I’ve been working with a client who’s been having a lot of trouble setting up Google Shopping ads.
After creating a product feed and submitting it to Google Merchant Center nearly half the products were listed as “Disapproved”. Drilling into these products in Google Merchant Center product details we saw the following error.
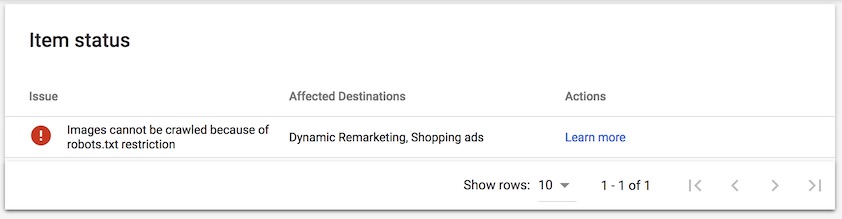
This stuck me as strange as, upon a quick check of the site’s robots.txt file I saw nothing that would prevent Googlebot from crawling the images in question.
We were ultimately able to resolve the issue, which, as suspected, had nothing to do with the robots.txt file. Here I’ll document my findings…
Learning More
The “Learn More” link took me to an article titled “Images cannot be crawled because of robots.txt restriction” in the Google Merchant Center Help Center.
There I found the following details…
What’s the problem?
Some of your items specify an image (via the ‘image link’ attribute) that cannot be crawled by Google because robots.txt forbids Google’s crawler to download the image. These items will remain disapproved until we are able to crawl the image.
The suggested fix was to update the site’s robots.txt file as follows…
User-agent: Googlebot
Disallow:
User-agent: Googlebot-image
Disallow:
Wait, What?
Upon reading this “fix” my jaw dropped to the floor ![]()
The suggested “fix” was in fact to remove any crawling restrictions across the entire site for Googlebot and Googlebot-image. The site in question was a Magento based ecommerce site where it’s standard to include some crawler restrictions in robots.txt. While in some cases (not ours) this “fix” may have “worked” as intended, it’s also likely to introduce all kinds of other (worse) SEO issues.
Giving It A Shot
Despite advising the client that this “fix” seemed potentially harmful and highly unlikely to fix the issue, we agreed to give it a shot (just to rule it out as the root cause of the issue). I updated the site’s robots.txt as documented in the Google Merchant Center Help Center and let Google re-crawl the feed.
After several days, however, the same amount of products remained disapproved…this “fix” obviously wasn’t the fix.
A Discovery From Left Field
At the same time that we were testing out the robots.txt update, we had engaged the site’s hosting company to assist with investigating the issue. We didn’t have full sudo privileges in this environment and as such we couldn’t have full visibility into what was happening on the server. After bouncing around between many Linux administrators with bogus diagnoses someone finally came back with an assessment that made some sense.
Apparently, the mod_evasive Apache module had been installed in the environment and was found to be blocking requests from Googlebot for the images in question. The Linux admin advised that mod_evasive had been configured as follows…
DOSPageCount 10
DOSPageInterval 3
DOSSiteCount 100
DOSSiteInterval 5
DOSBlockingPeriod 240
In plain English this means that if a single IP address requests the same URL more than 3 times within a 10 second interval OR sends more than 100 total requests to the site within a 5 second interval it will be blocked for 240 seconds.
His advise was to double everything, other than the DOSBlockingPeriod (the amount of time the IP address gets blocked).
Doing My Own Research
I did some quick research on the matter and found that we were not the only people who had seen this kind of issue. For example, there’s a post titled “Mod_Evasive Blocks Googlebot” on projectilefish tech blog which describes this exact issue.
Additionally, digging through the ticketing history with the hosting provider I found that mod_evasive had been implemented in response to an incident where the site in question was experiencing a brute force attack where the attacker was trying to guess an administrative password. Rate limiting makes sense in these cases, but it should be scoped to the paths that can be used as a brute force vector (rather than globally)…which is not something mod_evasive is capable of doing.
The Recommendation
Based on our research we advised the client to move forward with the hosting company’s recommendation. We weren’t very familiar with mod_evasive and found it to be a very primitive rate limiting solution which couldn’t effectively whitelist Googlebot. We were already discussing implementing Cloudflare as a CDN with the client, so we also brought up the fact the Pro plans come with a simple, but more flexible rate limiting solution.
The Result
After making some adjustments we were finally able to get Googlebot to crawl the entire feed with no disapprovals. Good job team! ![]()
![]()
![]()
The Lesson
The lesson here is that (like many Google tools) Google Merchant Center is a bit of a black box and the information and error messages need to be taken with a grain of salt. Unfortunately, this means that when there is an error it can be quite tricky to get to the bottom of it.
 Hi, I'm Max!
Hi, I'm Max!