Why and How Git Tags Can Save Your Sanity
Published: September 1, 2016
I want to talk to you about tags in git. If you’re already using them great! You may not need to read this post (although you’re of course welcome to). I’m guessing, however, that there are a good number of you who aren’t. If you fall into the latter category, read through the below to find out what you’re missing out on.
The Site Is Broken
When a production issue arises one of the first questions to ask is “what changed recently”. Git on it’s own is great for showing you a chronological list of changes to the source code. However, there’s one critical piece of information missing. When did this code go to production? This is where tags can help. I’ve been working to standardize a format at Something Digital, but currently I use GitHub’s release notes feature to publish all the changes that compose a given release, along with the date and time that the release was promoted to production. The format looks like this.
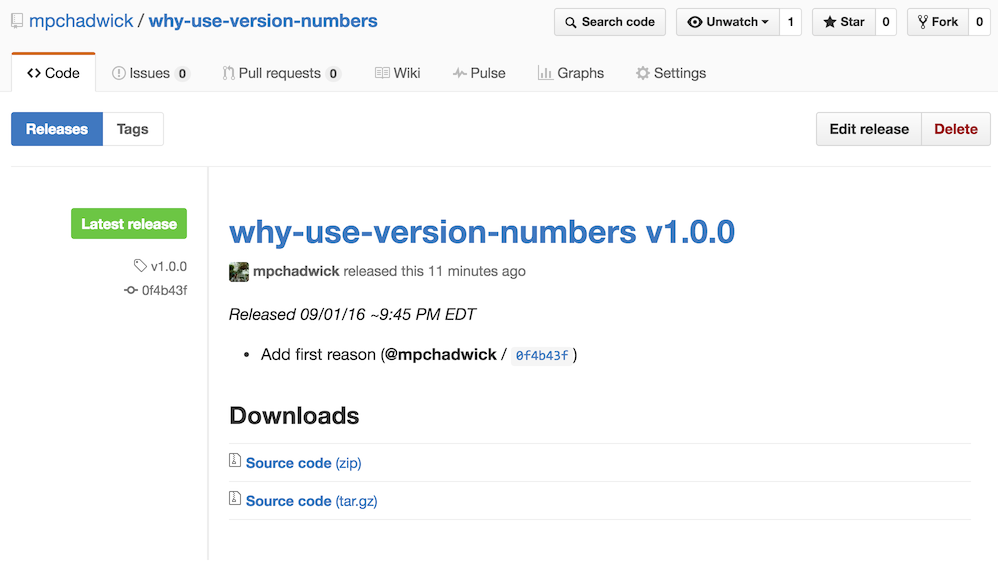
Following this format, if a production issue comes up, any developer can simply looks at the releases tab in Github and find…
- Date and time for each set of changes that went to production
- Detailed description of each individual change
- Developer who wrote the code
- Link to specific code (commit hash or pull request number)
I can’t count the number of time this has come in handy.
Rollbacks
When you’re using tags, part of your deployment process should be to checkout a specific tag. At Something Digital we’re using Samson which provides a web interface where we can specify the tag to deploy (we’re leveraging Capistrano behind the scenes).
Continuing on with the thought above about something being broken in production, rollbacks are much simpler when your using tags as (in theory) they indicate stable snapshots of the project code that is safe to be moved to production. If you’re just deploying master each time, it becomes much more challenging to know which commit is safe to roll back to, but with tags, you can just check out the previous version.
A Common Parlance
A non-technical, but equally valuable reason to use tagging (and versioning in general) is that it provides a common parlance when talking about the change history with stakeholders for a given project. Saying “The feature which allowed us to apply a coupon code from a URL parameter was the focus of release v10.3.0, but we found a critical bug which was resolved in v10.4.1” sounds much more polished than “The feature was added in a deployment that went live on September 14th, then we fixed a critical bug in it on October 4th”.
Auditing
Occasionally, someone might say, “I need a list of all the deployments we did over the course of the last year”. If you’re using tags (especially with the release notes system shown above), this is a snap. You could even help that individual set up a Github account and provide directions on how to access the “Releases” area so that the individual could have all the information easily accessible as his or her fingertips. The same can’t be said about non tag based deployment strategies.

I generally advocate lining up any major configuration changes to coincide with production releases and make note of them in the releases notes too so that they are available for auditing in the same fashion.
Semantic Versioning
Finally, version numbers can be used to express some information about the changes in a given releases. Semver specifies a MAJOR.MINOR.PATCH scheme for version numbers as follows…
- Bump the major version number when you introduce a change that is not backwards compatible
- Bump the minor version when you add new functionality
- Bump the patch version when you’re fixing a bug
Concerns about “non backwards compatible changes” are more relevant for libraries or code that powers an API that is consumed but unknown entities, than they are for people who build websites. For the case of creating websites I like to interpret as follows…
- Bump the major version for a large scale project
- Bump the minor version for smaller functional enhancements
- Bump the patch version for bug fixes
Conclusion
I hope this motivated some of you to consider using git tags and version numbers as part of your software version management process. If you already are doing both of those things and you got this far, good for you! As always, feel free to leave any thoughts in the comments below or teach out to me on Twitter.
 Hi, I'm Max!
Hi, I'm Max!