Blog
Etiquette When Addressing Code Review Comments
Published: December 4, 2017
Code review etiquette is an interesting subject.
A few months back an article was published to CSS-Tricks titled “Code Review Etiquette”. It outlines some general pointers for reviewers to keep in mind when doing code reviews.
In this post, I’ll make some etiquette suggestions that apply to a more specific part of the code review process…addressing code review comments.
We’ll look at this from the perspective of both the reviewer and the contributor.
Checking If An Array Is Empty In Ruby
Published: December 3, 2017
Recently, I was working on some Ruby code where I had to check if an array is empty. It turns out there are many ways to skin this cat. Here I’ll document my learnings…
My Journey To 100
Published: November 22, 2017
This is my 100th blog post ![]()
Rather than publishing a standard post about one of my favorite topics (such as Magento, security or caching) I’ve decided to do something special.
Here I’ll chronicle a 4 year journey starting with my very first blog post in December of 2013 leading up to the present day with my 100th blog post.
Syntax Highlighting And Color Contrast Accessibility
Published: November 16, 2017
Recently I watched a video titled “Totally Tooling Tips: Accessibility Testing” published to the Google Chrome Developers YouTube Channel.
The video demos Chrome’s built in accessibility audit tool.
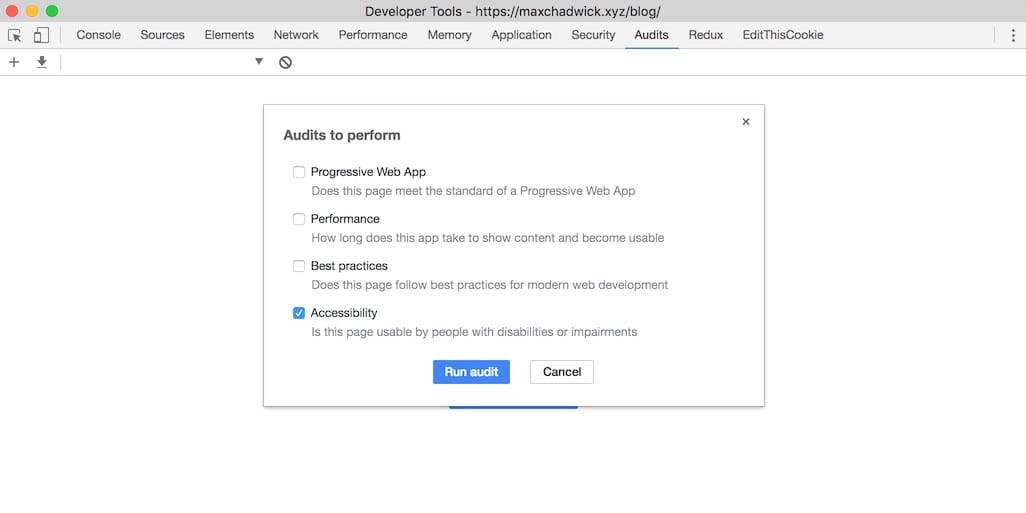
After watching the video I decided to run the tool against this site.
There were a few things I needed to fix to get this site to pass the audit. One of those things was the color contrast of the syntax highlighting I use for code snippets.
In this post I’ll explore that problem and talk about my approach to solving it.
Magento and New Relic Error Rate
Published: November 13, 2017
New Relic’s Error rate monitoring and alerting feature is a great way to catch unforeseen issues in production. However, properly using the feature requires an understanding of what is actually being measured.
In this post, we’ll take a look at what what New Relic’s “Error Rate” means for Magento applications.
Magento Config Cache Stampeding Race Condition
Published: October 30, 2017
It started with an alert.
CPU usage had climbed to above 80% on the web servers. Additionally, average response time had spiked.
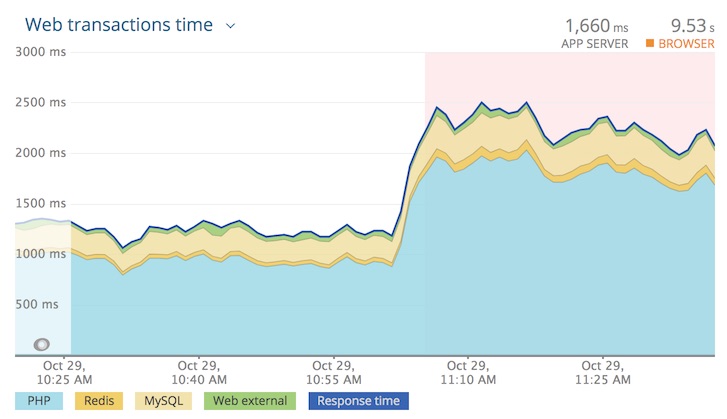
In New Relic APM Pro, we could see in some slow transaction traces that the server was busy loading XML configurations…which should’ve been coming from cache.
After a few hours of investigation, we found that the issue was due to a core bug which can result in cache stampeding due to a race condition when the site is under high load.
Let’s dive into the issue.